Seguimos moviendo partículas, ésta vez con OpenCL
Y ahora le toca el turno al segundo trabajo práctico de HPC\@UNS. Ésta vez vamos a seguir moviendo partículas, pero con mayor grado de paralelización, ya que vamos a usar OpenCL sobre una placa nVidia GeForce 8800 GTS 512 (rev a2) y Debian.
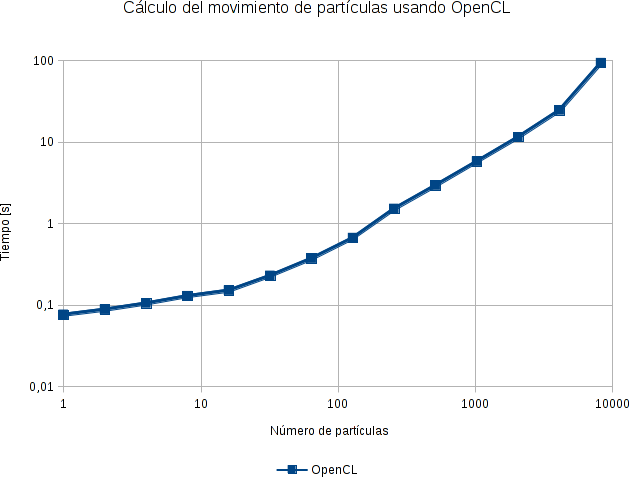 Cada punto del gráfico es el promedio de 5 corridas del mismo algoritmo con los mismos parámetros.
Cada punto del gráfico es el promedio de 5 corridas del mismo algoritmo con los mismos parámetros.
Por si solo no nos dice mas que el algoritmo tiene una dependencia O(n²) con el número de partículas. Ésto es natural ya que se trata del mismo código serial que en el práctico anterior, ésta vez convertido a OpenCL.
Nota: el código original está bajo la licencia BSD modificada (¡Gracias Vasily Volkov!). El código modificado mantiene la licencia.
Como en el caso del práctico anterior, se pueden tomar otras estrategias para reducir el orden de complejidad del código... pero no es lo que nos intereza ahora. La idea es comparar estos resultados con los ya obtenidos. Pero antes...
Nota importante: el código de OpenCL utiliza floats en vez de doubles para los cálculos. Ésto es debido a que la placa gráfica no soporta éste último tipo. Ésto llevó a la necesidad de aumentar la masa de la partícula, ya que el valor original producía errores numéricos que producían que las partículas se aceleraran.
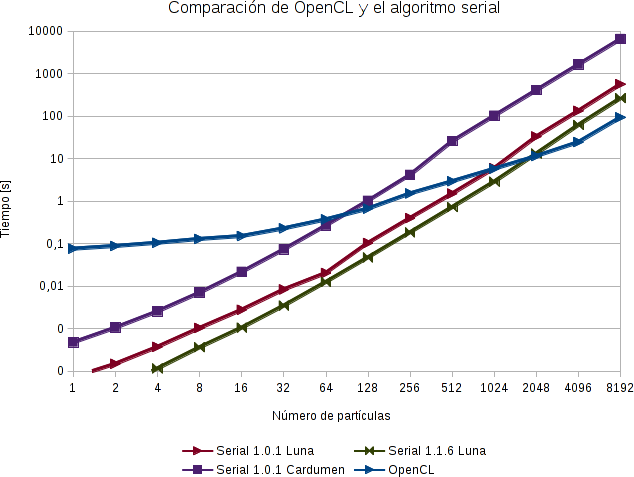
Lo primero que podemos observar es que el tiempo de cálculo requerido para un número de partículas menor a \~[64 128] (según la implementación y el host) es menor para el caso serial que para el caso con OpenCL. Ésto era de esperarse, ya que se consume un tiempo importante en pasar datos hacia y desde la placa de video al host. Es decir, vale la pena implementar éstas soluciones si el número de datos a procesar es grande.
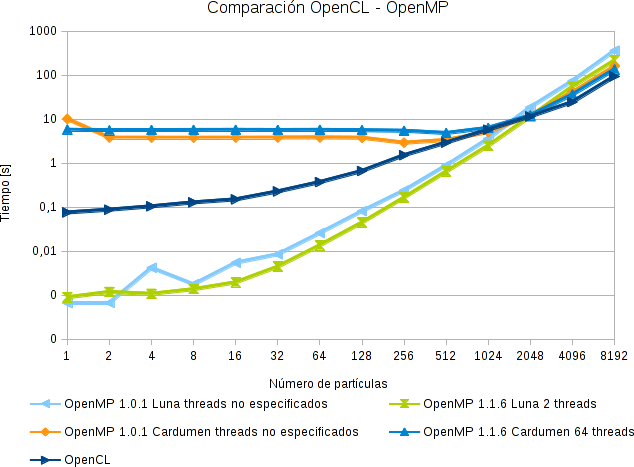
Es interesante notar como OpenMP sobre Luna (AMD Athlon (tm) 64 X2 Dual core processor 5000+) presenta mejor tiempo de cálculo que OpenCL para menos de 1024 partículas. A su vez, la implementación de OpenMP en cardumen (UltraSparc T2 (Niagara2)) es mas lenta. A medida que el volumen de datos aumenta, OpenCL comienza a ser mas eficiente.
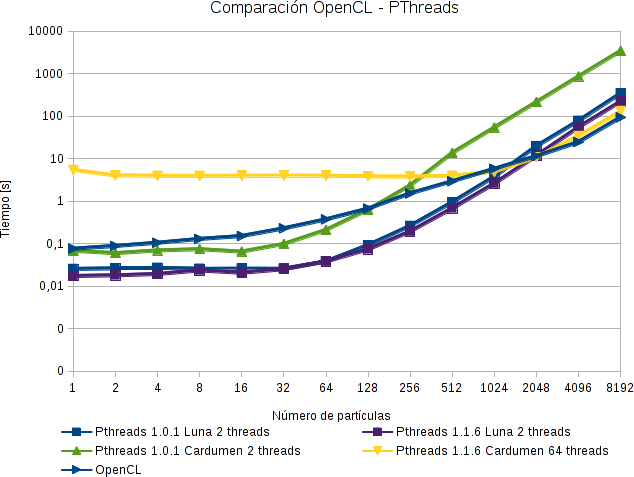
Las comparaciones para PThreads son bastante similares a las anteriores. Tarea para el lector :-)
Notas y conclusiones
- OpenCL tiene muy buen desempeño para volumenes de datos grandes, aunque vale la salvedad de que se utilizaron floats en vez de doubles. Quizás si algún dia pongo mis manos en una placa con soporte para doubles pruebe a ver que pasa.
- OpenCL es un estándar, pero sólo provee los headers (API). Las implementaciones dependen de cada fabricantes, y no son software libre, al menos por ahora. Ésto atenta contra la portabilidad del código.
- QtOpenCL está genial :-)
Comments
There are no comments yet.